Google set a new record for ImageNet1K: Don’t throw away the fine-tuning model with poor performance, and you can improve the performance by finding the average weight.
Abundant colors come from concave temples.
Quantum bit | WeChat official account QbitAI
How to maximize the accuracy of the model?
Recently, institutions such as Google found that:
Don’t throw the fine-tuning model with poor performance, and find the average weight!
The accuracy and robustness of the model can be improved without increasing the reasoning time and memory overhead.
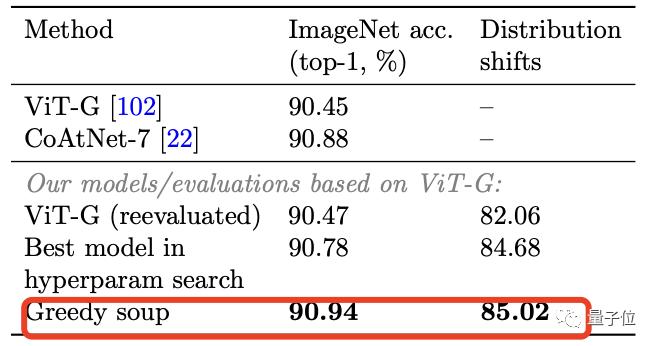
For example, researchers used this method to create a new record of ImageNet1K: 90.94%.
Extending it to multiple image classification and natural language processing tasks can also improve the out-of-distribution performance of the model and improve the zero-sample performance of new downstream tasks.
And this method also has an interesting name, module soup-
Is it immediately reminiscent of Fibonacci soup jokes? (Yesterday’s soup+the day before yesterday’s soup = today’s new soup)

△ Zhihu netizen @hzwer, authorized.
There are three formulas.
Think back, before this, how did everyone increase the model?
Do you first train multiple fine-tuning models with various superparameters, and then pick out the one with the best performance in the verification set and leave the rest?
Because neural network is nonlinear, there may be many solutions in different loss basin, so it is a little surprising that Module soup can improve its performance by keeping the weights of all fine-tuning models and averaging them.
Recently, however, it has been found that the fine-tuning models optimized independently from the same initialization configuration are in the same error range (lie in the same basis of the error landscape).
Previous studies have proved that the performance of random initialization training model can be improved by averaging the weights along a single training trajectory.
It is from these conclusions that the author is inspired.
There are three "recipes" (realization) of Module soup: uniform soup, greedy soup and learned soup.
Among them, greedy soup is the most important implementation, because its performance is higher than directly and evenly averaging all weights.
Specifically, Greedy soup is built by sequentially adding each model as a potential component in the "soup", and the corresponding model is only kept in the "soup" when the performance on the verification set is improved.
Sorting is in descending order of verification set precision.

Performance beyond a single optimal fine-tuning model
The author conducted a comprehensive fine-tuning experiment to determine the effectiveness of Module soup.
The first is to fine-tune CLIP and ALIGN. These two models are pre-trained on image-text pairs.
Results After the operation of module soup, both of them performed better in distribution and distribution shifts test set than the best single fine-tuning model.
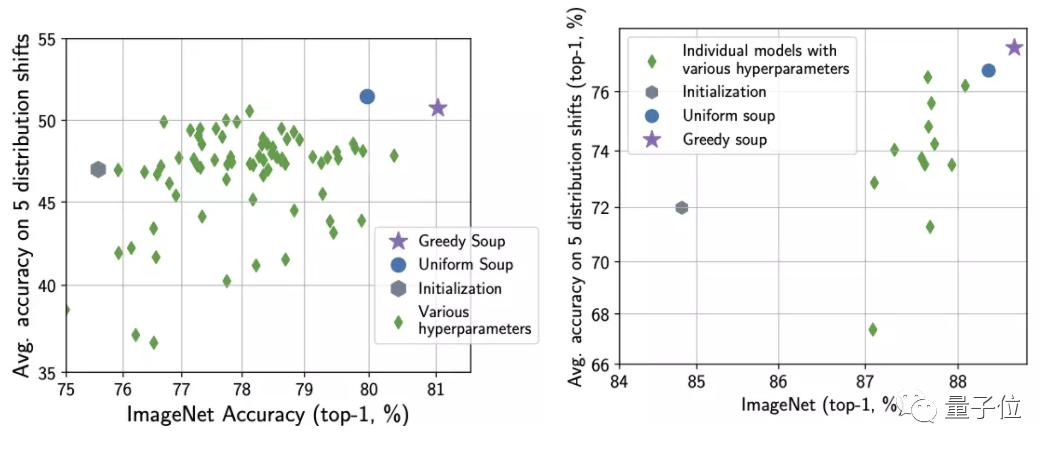
△ left is CLIP and right is ALIGN.
Then the ViT-G model pre-trained on JFT data set.
That is to say, it achieves 90.94% accuracy in ImageNet1K data set, breaking the previous 90.88% maintained by CoAtNet, and at the same time reduces 25% FLOPs in the reasoning stage.
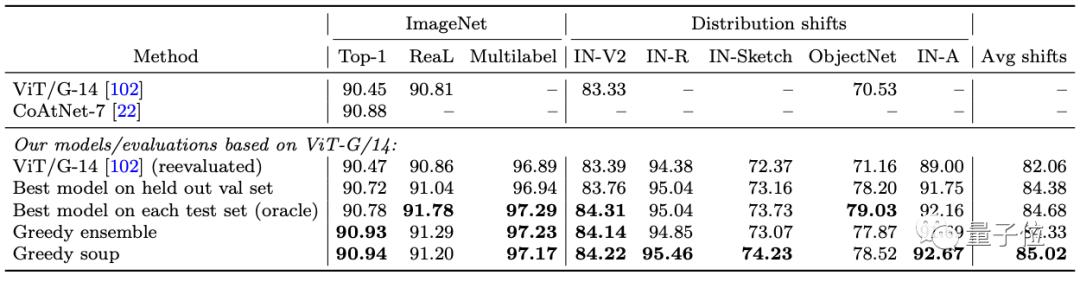
In addition to the task of image classification, the author also verified module soup in NLP field.
The following table shows the results of BERT and T5 models on four text classification tasks of GLUE benchmark:

It can be found that although the improvement is not as obvious as that in image classification, in most tasks, greedy soup can improve the performance compared with the best single model.
Of course, the author also pointed out that there are limitations in the applicability of module soup, such as the models that are pre-trained on large heterogeneous data sets, and the effect is not very obvious outside these models.
Finally, a netizen from Zhihu @ 京京京京京京京京京京京京京京京京京京京京京京京20140

Did you find out?
Paper address:
https://arxiv.org/abs/2203.0548
Zhihu @ Gong Sauce Craftsman, @hzwer Answer (Authorized): https://www.zhihu.com/question/521497951.
End—
Original title: "Google creates a new record of ImageNet1K: Don’t throw away the fine-tuning model with poor performance, and find the average weight to improve performance."